

Las máquinas de factorización son predictores generales (trabajar con cualquiera los vectores de características posibles) incluso en condiciones de datos muy sparse, todo esto teniendo complejidad lineal sobre el numero de datos y dimensiones latentes escogidas para escalar eficientemente.
Logran esto usando descomposición matricial (a un espacio de menos dimensiones) de una matriz construida específicamente para este fin como la mostrada en la siguiente imagen:
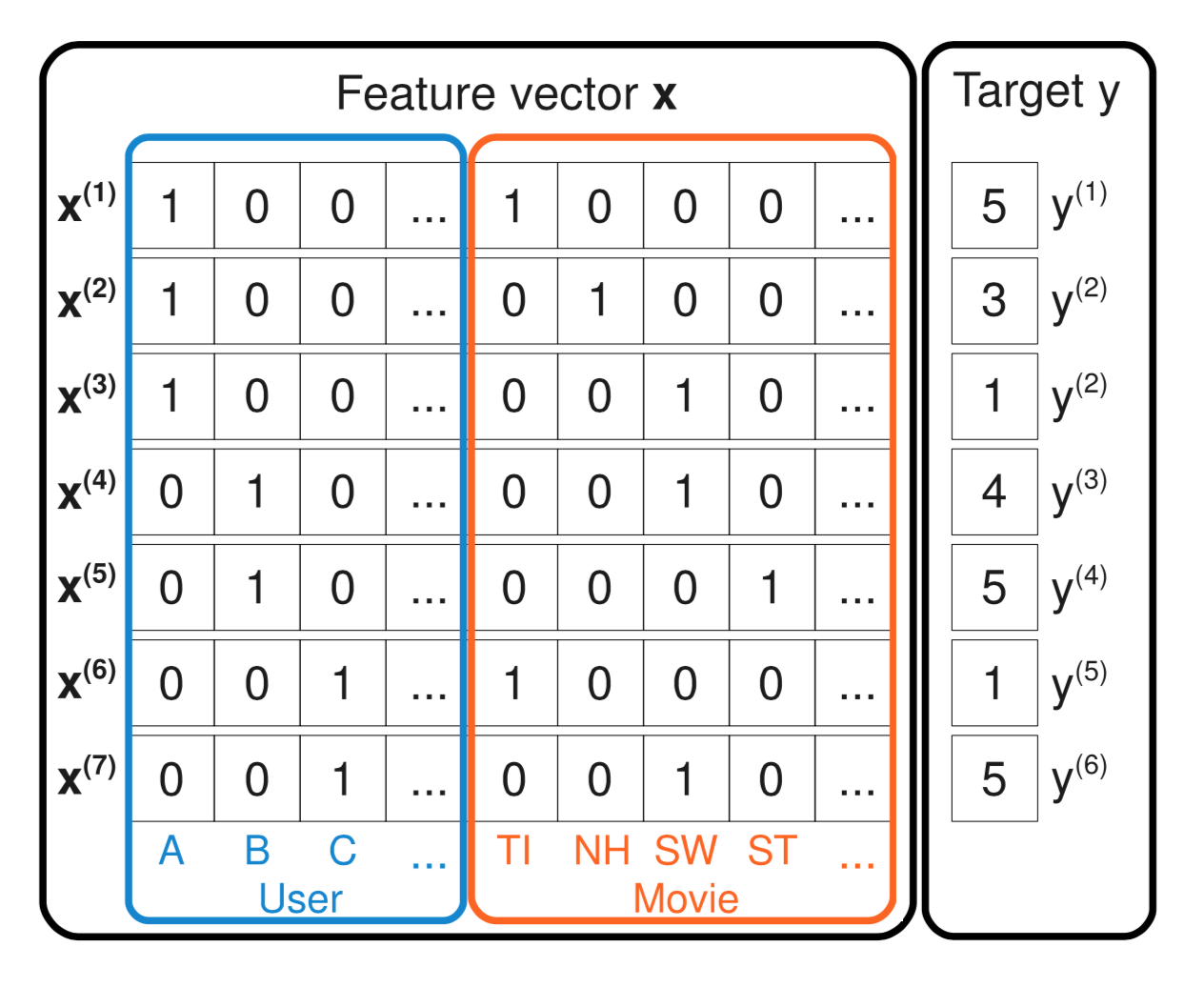
La intuición clave acá es considerar los recuadros User, Movie y Target. Cada fila representa una interacción entre un usuario y un ítem. Por ejemplo, la primera fila muestra que el usuario A (Alice) interactuó con el ítem TI (Titanic) y lo calificó con 5 puntos. La factorización de la matriz llevará columnas con interacciones similares (o cualquier patron reconocible por el modelo) a formar columnas similares en el espacio de dimensiones reducidas. Luego, el producto punto entre estas columnas similares será alto (ver mi post de la semana 2 para una explicación sobre la relación entre el producto punto de dos vectores y su distancia euclidiana). Esta relación está implícita en la ecuación del modelo mostrada a continuación donde se ve que al intentar predecir, por ejemplo, el puntaje que dará Alice al elemento Star Trek (ST) la multiplicación de $x_i = x_{Alice}$ con $x_j = x_{Star Trek}$ será la única multiplicación entre $x$ con resultado no cero, y luego la unica parte de la tercera componente de la ecuación será la similaridad entre los historiales de Alice y Star Trek.
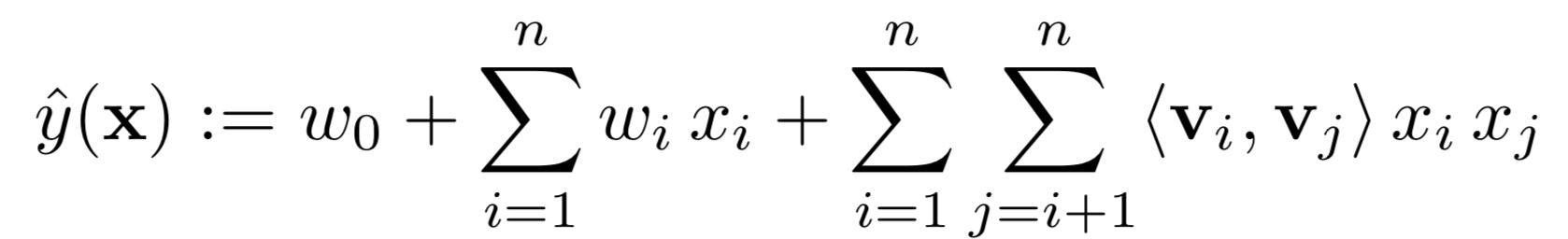
También se pueden agregar otros elementos a la matriz (otra de las ventajas de ser predictores generales) para considerar el historial del usuario, la fecha y hora a la que consumió el elemento, etc. Incluyo una imagen con estos datos para ilustrar como se incluyen, donde aprovecho de destacar la normalización cuando hay varios elementos dentro del mismo campo (como es el caso de Other Movies Rated).

Tengo dos comentarios principales que hacen referencia (en ese orden) a la forma de modelar el tiempo (Time en la imagen arriba) y a la memoria necesaria para entrenar el modelo.
Primero consideremos la codificación del tiempo. EL autor convierte información rica en un contador de meses desde alguna fecha no explicada (presumiblemente la fecha que se tiene para la primera interacción). Tiene sentido que un usuario prefiera distintas películas a distintas horas o dias de la semana, meses, etc. Una mejor forma de codificar el tiempo (y compatible con el modelo en discusión) podría ser codificar el año, mes, día de la semana y momento del día. La consideración del valor que tome $w_i$ para la cada una de las columnas agregadas nos debiera mostrar la relevancia de esta variable para la predicción por lo que resulta deseable la codificación no solo para mejorar el rendimiento del modelo (pasándole información más rica) sino también aumentar su explicabilidad (y quizás hasta la confianza del usuario en el sistema si se le da acceso a esta información).
Habría sido interesante que el paper comentara sobre es si es posible paralelizar el modelo en múltiples nodos para reducir la cantidad de memoria necesaria por nodo para almacenar la matriz (que obviamente ocupa mucho mas espacio que la fomulación tradicional $R^{UxI}$). La versión original de la ecuación de modelo requiere que todos los nodos contengan la matriz $V$ (o que compartan memoria, lo que lleva a necesitar sincronizar y perder la ventaja de paralelizar), sin embargo la versión reformulada admite paralelización distribuyendo $V$ entre tantos nodos como hayan disponibles (!).
Las FM son modelos potentes que aceptan gran variedad de información (que también puede ser codificada de diferentes maneras). Su flexibilidad permite codificar información de diferentes maneras y aporta algo de explicabilidad a los modelos de factorización tradicionales al incluir en $w$ una métrica de la relevancia de cada columna de $W$.